Εκπόνηση από:
- Γιώργος Ζορπίδης - 1115202000055
- Γιάννης Κώτσιας - 1115202000113
Για όλες τις συναρτήσεις χρησιμοποιήθηκε η κλήση μέσω της TC (Tested Call) για πιο εύκολο debugging και για να μην ξαναγράφουμε πολύ κώδικα.
Για το heap file η εικόνα είναι παρόμοια της εικόνας που δίνεται
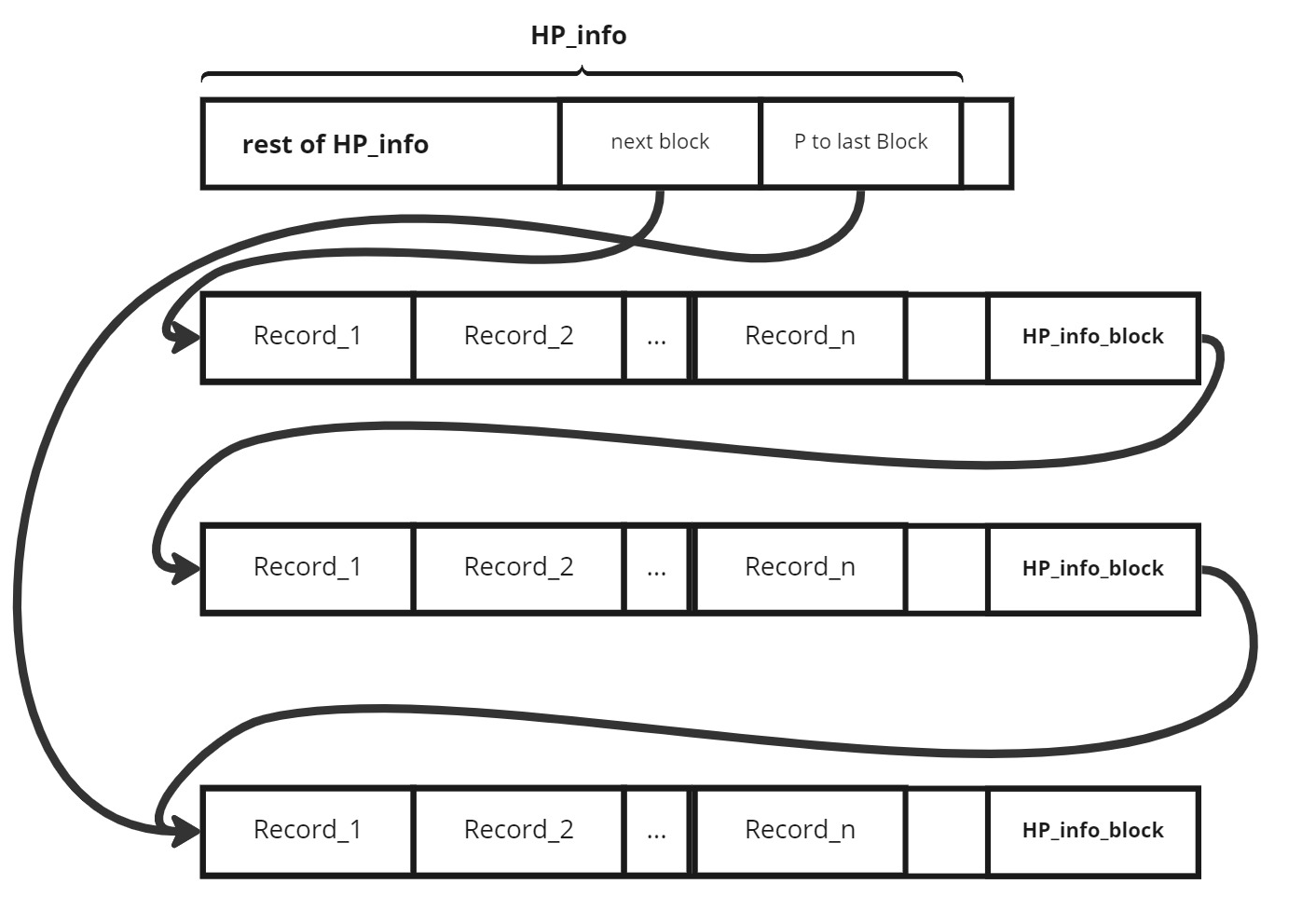
Δημιουργούμε το αρχείο φτιάχνοντας το πρώτο μπλοκ που κρατάει τα μεταδεδομένα και αρχικοποιούμε τα επόμενα και τελευταία μπλοκ με -1. Κατά την εισαγωγή ελέγχουμε: Αν υπάρχει μόνο ένα μπλοκ μέσα, θα πρέπει να δημιουργήσουμε το επόμενο, να βάλουμε την εγγραφή και έπειτα να συνδέσουμε το πρώτο μπλοκ ώστε να δείχνει στο επόμενο και στο τελευταίο μπλοκ στο νέο allocated block. Αλλιώς, πρέπει να δούμε το αν το τελευταίο μπλοκ είναι γεμάτο ή όχι. Αν δεν είναι γεμάτο, τότε απλά βάζουμε την εγγραφή στην ελεύθερη θέση, αλλιώς: Φτιάχνουμε ένα νέο μπλοκ και πρέπει αφού βάλουμε την εγγραφή να βάλουμε στο προ τελευταίο (πλέον, παλιό τελευταίο) μπλοκ να δείχνει ως "επόμενο του" το καινούριο μας μπλοκ, και το πρώτο μπλοκ να δείχνει ως νέο τελευταίο μπλοκ στο νέο καινούριο μας μπλοκ.
Για να βάλουμε το HP_info_block στην τελευταία θέση πρέπει να πάρουμε το αρχικό δείκτη των δεδομένων να πάμε δεξιά όσο το μέγεθος του μπλοκ και μετά πίσω, όσο είναι το μέγεθος του HP_info_block.
Η getAllEntries όταν βρει το match στο id λήγει την περαιτέρω αναζήτηση. Η λειτουργία της είναι σχετικά απλή αφού σειριακά πηγαίνει από το κάθε μπλοκ στο επόμενό του, ελέγχοντας τις εγγραφές ενός του για κάποιο match.
Για το Static hashing αρχείο: Στο πρώτο μπλοκ θα πρέπει να κρατήσουμε μερικά δεδομένα και μετά το ίδιο το hashTable. Επειδή γνωρίζουμε ότι το hashTable είναι πρακτικά ένας πίνακας δεικτών προς μπλοκ, και πρέπει να χωράει μέσα στο πρώτο μπλοκ, τότε ορίζουμε ένα μέγιστο μέγεθος κουβάδων στο 30. Ωστόσο ως δείκτες εμείς ορίζουμε πρακτικά έναν ακέραιο αριθμό, το αναγνωριστικό blockId κάθε μπλοκ.
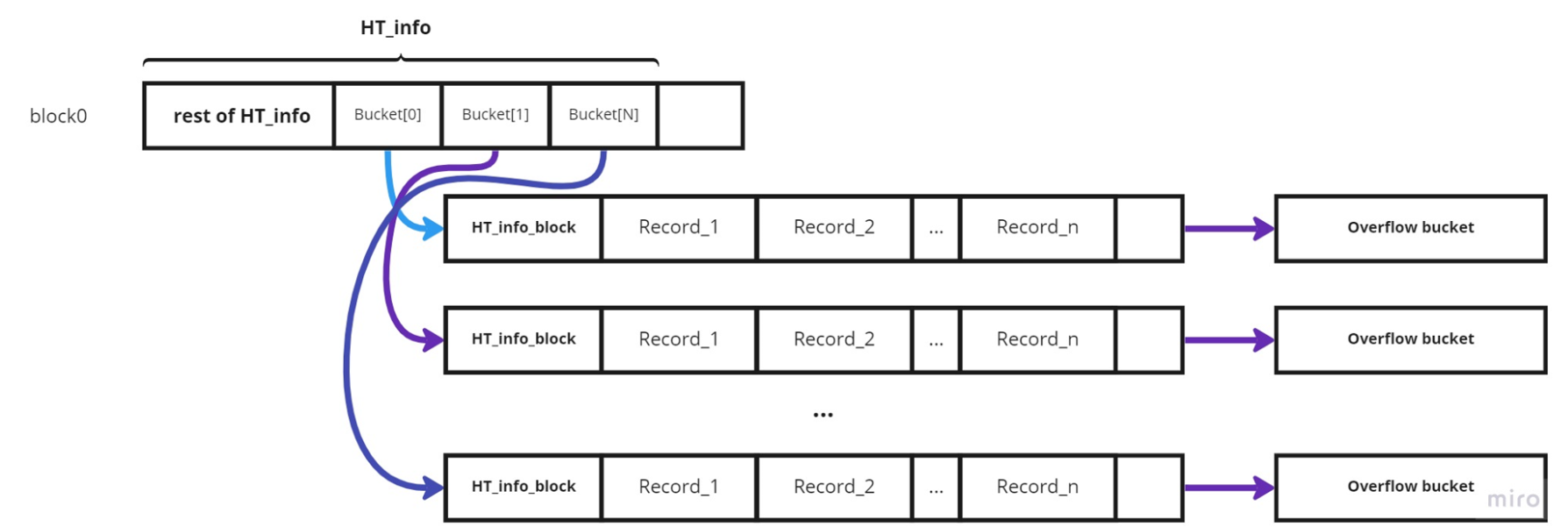
Κατά την δημιουργία του αρχείου, αρχικοποιούμε τους κουβάδες ώστε να δείχνουν στα αρχικά μπλοκ. Έτσι κάνουμε το block allocation των κουβάδων proactively, αντί να κοιτάμε στο insertion αν η θέση είναι NULL (δηλαδή -1) και να κάνουμε allocate το μπλοκ εκείνη την στιγμή.
Κατά την εισαγωγή, hashάρουμε το ID με βάσει την hash function (εμείς ορίσαμε να είναι απλά το ID % (αριθμό κουβάδων). Αυτό μας δείχνει το σε ποιον "κουβά" θα μπεί η εγγραφή. Κατά την εισαγωγή ,επίσης,ακολουθήσαμε την τεχνική που περιγράφηκε κατά την παρουσίαση/φροντιστήριο της εργασίας, κατά την οποία: ΑΝ το μπλοκ στο οποίο δείχνει ο κουβάς είναι γεμάτος, δημιουργούμε ένα νέο μπλοκ, βάζουμε την εγγραφή, και έπειτα: α) Ορίζουμε ο κουβάς να δείχνει στο νέο μπλοκ, και β) το νέο μπλοκ να δείχνει στον παλίο μπλοκ το οποίο είναι γεμάτο ως επόμενό του. Επομένως η επόμενη εισαγωγή η οποία θα χασάρει στον "κουβά" αυτόν, θα μπει στο μπλοκ με το 1 μόλις στοιχείο.
Π.χ. Έστω ότι έχουμε 5 κουβάδες. Τότε κατά την αρχικοποίηση ο κουβάς για τα στοιχεία 0 θα δείχνει στο μπλοκ 1, ο κουβάς για τα στοιχεία [1] θα δείχνει στο μπλοκ 2, κλπ. Έστω ότι έχουμε εξαντλήσει το μέγεθος του κουβά [0], χωρίς να έχουμε κάνουμε allocate άλλου μπλοκ. Η επόμενη εισαγωγή στον κουβά [0] θα δημιουργήσει το μπλοκ 6, και θα θέσει τον κουβά [0] να δείχνει στο 6, ενώ το 6 θα δείχνει στο παλιό μπλοκ, δηλαδή στο 1.
Η ιδέα αυτή φαίνεται και παρακάτω:
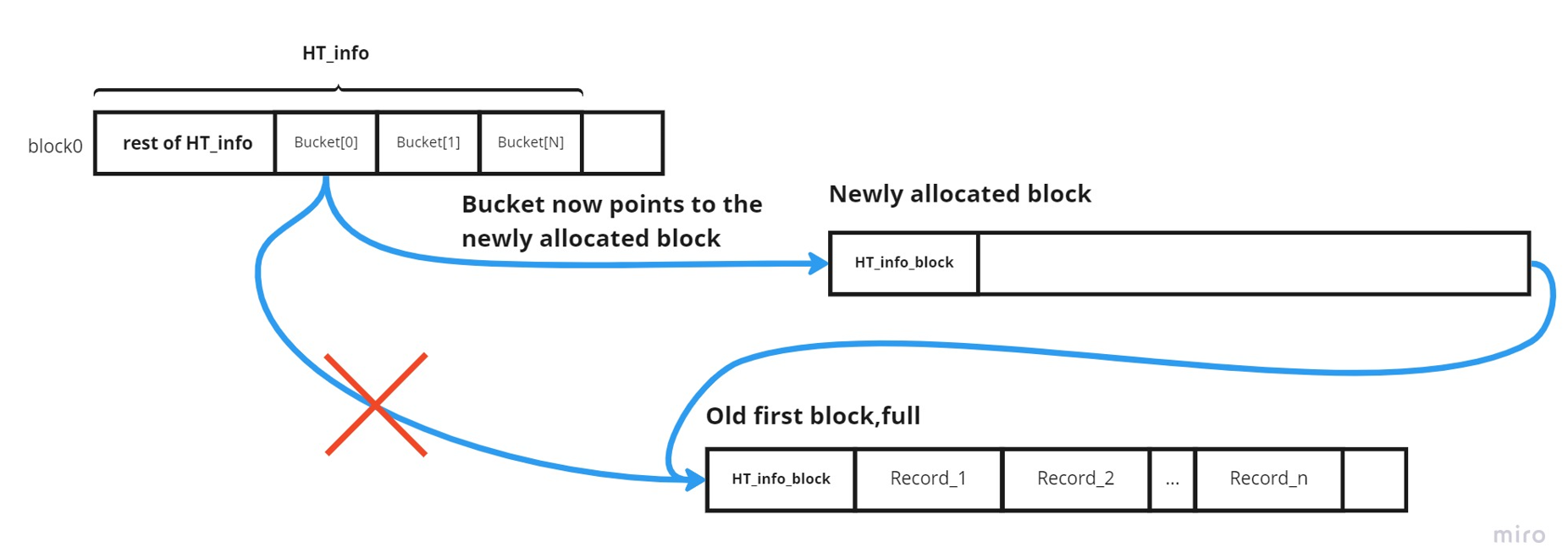
Η GetAllEntries θα κοιτάξει λοιπόν όλο το chain των buckets (και overflow buckets αν υπάρχουν) για το id το οποίο δίνεται, και έπειτα σειριακά όλα τα στοιχεία μέχρι να τα βρει.
Τα αρχεία sht_table.h, sht_table.c, sht_main.c πρέπει να αποθηκευτούν στους φακέλους include, src, και examples αντίστοιχα, ενώ το Makefile αντικαθιστά το παλιό Makefile. Για την διαγραφή των αρχείων που δημιουργούνται χρειάζεται η κλήση της make clear.
Για την εργασία 2, δημιουργούμε το Secondary Index το οποίο βασίζεται σε μέγαλο βαθμό στην ίδια λογική του Hash Table. Η λογική διαφέρει στο ότι: Εμείς δεν αποθηκεύουμε στο δευτερεύον ευρετήριο μια ολόκληρη εγγραφή πλέον, αλλά μια διάδα του ονόματος και του μπλοκ στο οποίο βρίσκεται μια εγγραφή στο πρωτεύον ευρετήριο (η οποία επιστρέφεται από το insert της HT).
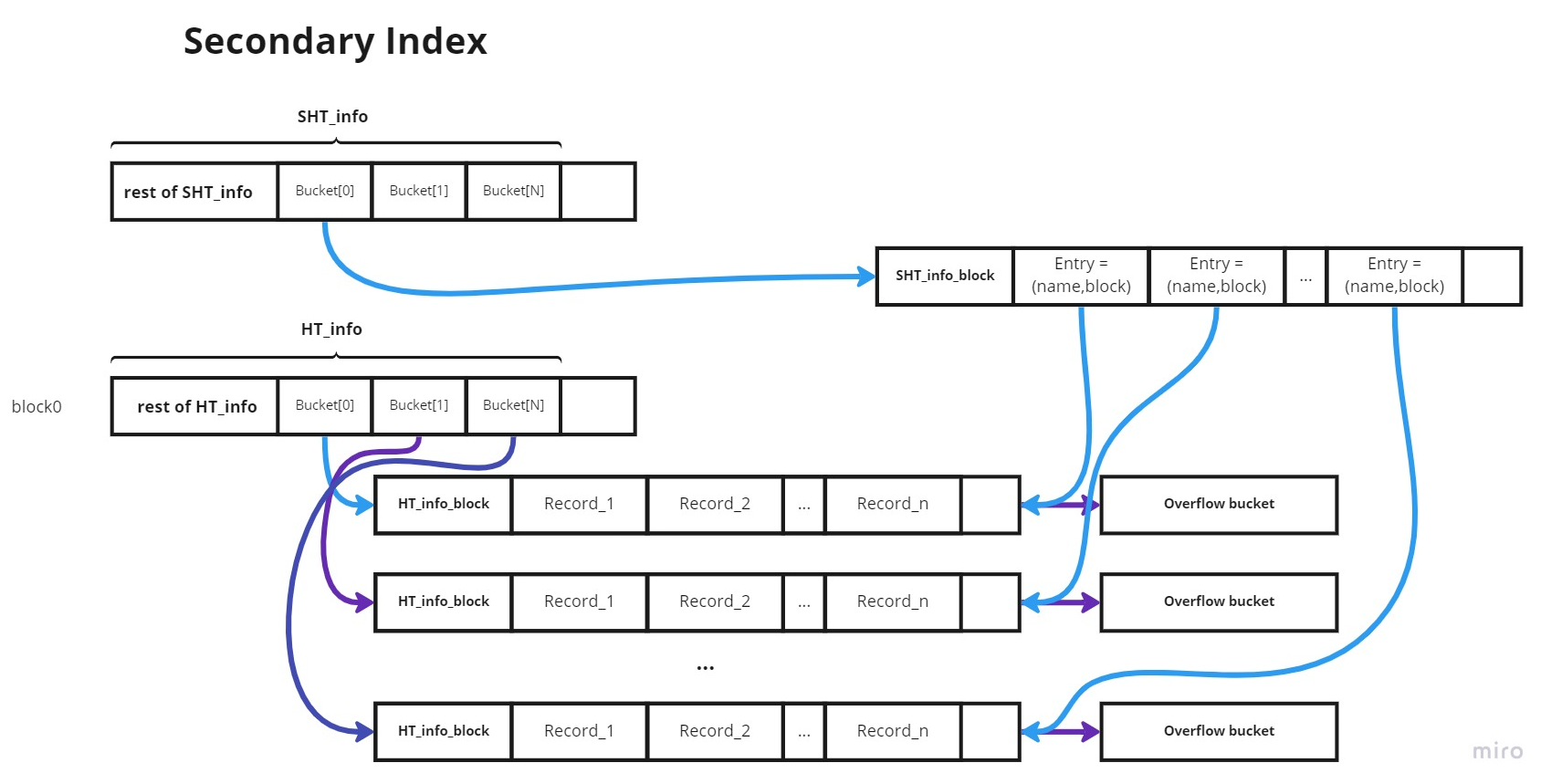
Ένα σημαντικό edge case το οποίο αναφέρθηκε στο eClass είναι ότι, έστω ότι βάζουμε δύο εγγραφές ("Μαριάννα", 1, ...), και ("Μαριάννα", 11, ...) στο πρωτεύον ευρετήριο, τα οποία όμως μπαίνουν στο ίδιο μπλοκ του, π.χ. το 1. Εμείς στο δευτερεύον ευρετήριο θα βάλουμε <"Μαριάννα", 2> και <"Μαριάννα",2>, εκεί που χασάρει το όνομα "Μαριάννα". Αμα τα εισαγαγάμε κανονικά, τότε στην GetAllEntries για το όνομα "Μαριάννα" θα βλέπαμε αρχικά το 1ο <"Μαριάννα",2> και θα πηγαίναμε στο 2ο μπλοκ του primary index, στο οποίο όπως περνάγαμε θα βρίσκαμε τις 2 εγγραφές. Μετά όμως θα βλέπαμε το 2ο <"Μαριάννα",2> και θα ξαναπηγαίναμε στο 2ο μπλοκ του primary index στο οποιο θα ξαναβρίσκαμε τις εγγραφές. Κάτι τέτοιο όμως δεν το θέλουμε. Αν γράφαμε C++ θα μπορούσαμε να κάναμε χρήση ενός std::map/std::set το οποίο να κράταγε τα visited block. Επειδή δεν ξέραμε αν κάτι τέτοιο θα επιτρεπόταν, αποφασίσαμε προτού να κάνουμε την εισαγωγή να ελέγχουμε αν υπάρχει διπλότυπο στον κουβά. Κάτι τέτοιο δεν είναι ιδιαίτερα αποδοτικό ωστόσο, αφού μπορεί να χρειαστεί να κατεβαίνουμε ένα μακρύ chain.
Η getAllEntries είναι ιδιαίτερα περίπλοκη στον κώδικά της, αφού θα πρέπει να κατεβαίνουμε το chain στο secondary index, να ελέγχουμε το αν το δωθέν όνομα είναι στην διάδα secIndexEntry και αν είναι να λαμβάνουμε το μπλοκ στο primary index, και να περνάμε από όλο το μπλοκ αυτό στο πρωτεύον ευρετήριο ώστε να βρούμε ένα match ονόματος.