Cohort building is an essential part of patient analytics. Defining which patients belong to a cohort, testing the sensitivity of various inclusion and exclusion criteria on sample size, building a control cohort with propensity score matching techniques: These are just some of the processes that healthcare and life sciences researchers live day in and day out, and that's unlikely to change anytime soon. What is changing is the underlying data, the complexity of clinical criteria, and the dynamism demanded by the industry.
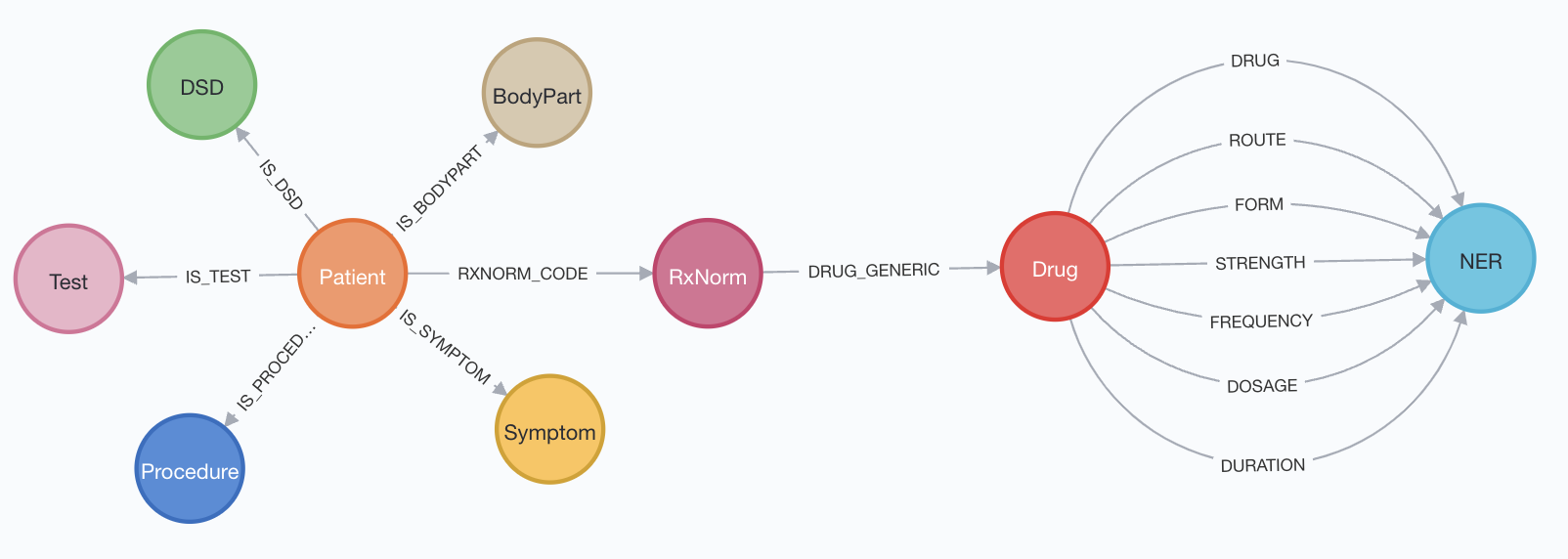 While tools exist for building patient cohorts based on structured data from EHR data or claims, their practical utility is limited. More and more, cohort building in healthcare and life sciences requires criteria extracted from unstructured and semi-structured clinical documentation with Natural Language Processing (NLP) pipelines. Making this a reality requires a seamless combination of three technologies:
(1) a platform that scales for computationally-intensive calculations of massive real world datasets,
(2) an accurate NLP library & healthcare-specific models to extract and relate entities from medical documents, and
(3) a knowledge graph toolset, able to represent the relationships between a network of entities.
In this solution accelerator from John Snow Labs and Databricks, we bring all of this together in the Lakehouse.
Read the blog here
While tools exist for building patient cohorts based on structured data from EHR data or claims, their practical utility is limited. More and more, cohort building in healthcare and life sciences requires criteria extracted from unstructured and semi-structured clinical documentation with Natural Language Processing (NLP) pipelines. Making this a reality requires a seamless combination of three technologies:
(1) a platform that scales for computationally-intensive calculations of massive real world datasets,
(2) an accurate NLP library & healthcare-specific models to extract and relate entities from medical documents, and
(3) a knowledge graph toolset, able to represent the relationships between a network of entities.
In this solution accelerator from John Snow Labs and Databricks, we bring all of this together in the Lakehouse.
Read the blog here
SparkNLP for healthcare
To create a cluster with access to SparkNLP for healthcare models, follow these steps or run the RUNME notebook in this repository to create a cluster with the models.
Neo4j
To build the knowledge graph, we use neo4j graph database. To learn more on how to stand up a graph database within your cloud environment, see the relevant depplyment guide:
To connect to your neo4j graph database from databricks, see Neo4j on databricks
Copyright / License info of the notebook. Copyright [2021] the Notebook Authors. The source in this notebook is provided subject to the Apache 2.0 License. All included or referenced third party libraries are subject to the licenses set forth below.
Databricks Inc. (“Databricks”) does not dispense medical, diagnosis, or treatment advice. This Solution Accelerator (“tool”) is for informational purposes only and may not be used as a substitute for professional medical advice, treatment, or diagnosis. This tool may not be used within Databricks to process Protected Health Information (“PHI”) as defined in the Health Insurance Portability and Accountability Act of 1996, unless you have executed with Databricks a contract that allows for processing PHI, an accompanying Business Associate Agreement (BAA), and are running this notebook within a HIPAA Account. Please note that if you run this notebook within Azure Databricks, your contract with Microsoft applies.