{kind=link}
{kind=link}
An introduction to understanding how noise protects privacy while preserving data utility. This guide explains the basic concepts of data noise through practical examples and visualizations.
Watch my video Lab Solution: Differential Privacy in Machine Learning with TensorFlow Privacy (Google Cloud Skills Boost) and learn these skills hands-on with Software Girls channel.
Adding noise to data is like applying a slight blur to a photograph: the fine details become harder to identify, but the overall structure remains clear enough for analysis. This balance allows researchers and analysts to uncover general trends while protecting individual privacy.
When we "blur" data, similar to a photograph:
- In data privacy, added noise can obscure the details that could identify individuals (fine details).
- However, the overall patterns, trends, or relationships in the data (general image) remain intact and useful for analysis.
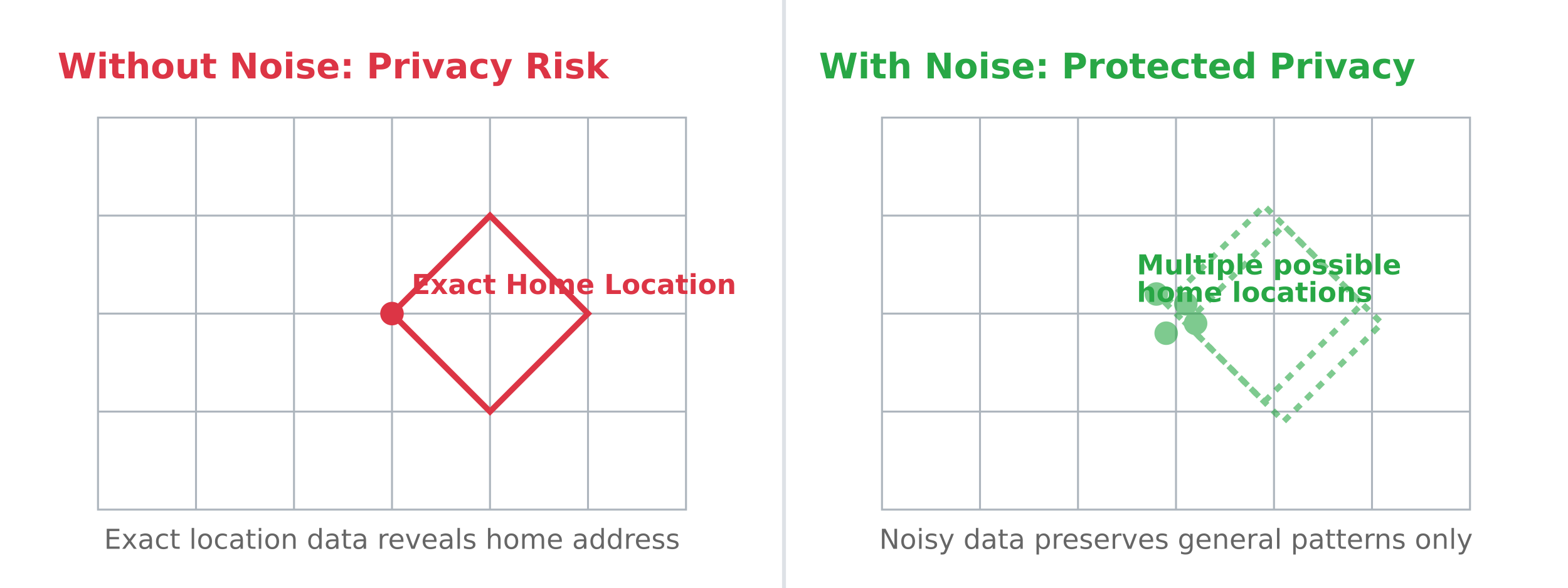
This visualization demonstrates how adding noise to location data protects individual privacy (like home addresses) while preserving useful patterns for analysis:
- Without noise: Researchers can see every patient's exact diagnosis and treatment history, which risks identifying individuals.
- With noise: Researchers only see approximate numbers or patterns (e.g., "around 20% of patients responded well to treatment"), which still allows them to draw conclusions about the effectiveness of treatments.
- Without noise: A dataset might show exact GPS coordinates of someone's home, which could compromise their privacy.
- With noise: The location is blurred slightly, so while researchers can study general movement patterns in a city, they can't pinpoint individual homes.
- The noise ensures no one can reverse-engineer the data to identify individuals (privacy).
- The aggregated patterns or averages remain accurate enough to inform decisions or generate insights (utility).
Different random functions introduce various types of randomization into your data. Some, like random.random() < 0.75, create a coin-flip effect with two outcomes. Others, like numpy.random.normal(), create continuous noise that follows a bell curve.
The simplest form of noise involves slightly modifying numerical values. For example:
- Age: 25 → 24.7 or 25.3
- Height: 5'8" → 5'7.8" or 5'8.2"
- Test scores: 85 → 84.3 or 85.7
For data that can't be slightly modified, we use the coin-flip method. This method provides strong privacy guarantees through randomization:
- Each person gets a virtual coin that determines if they tell the truth or give a random answer.
- The 75% truth rate maintains statistical accuracy.
- The 25% random rate provides strong privacy protection.
- This creates "plausible deniability"—if someone's answer is revealed, they can always say they were in the random group.
- With large numbers of responses, patterns remain clear while individuals stay protected.
Geographic coordinates get special geometric noise:
- A location might be shifted slightly in any direction.
- The shift is small enough to preserve general patterns.
- But large enough to prevent exact location tracking.
Apple uses differential privacy to gain insights into user behavior while protecting individual privacy. Here are two examples:
- Apple adds noise to emoji usage data collected from devices.
- This lets them determine overall emoji popularity trends.
- Individual users' emoji usage remains private, even if the data is leaked.
- Typing patterns are studied with added noise to improve autocorrect suggestions.
- No individual user's typing habits can be reverse-engineered.
By adding noise, Apple balances improving user experience with strong privacy protection. For more details, read their Differential Privacy Overview.
Even though noise adds randomization, the data remains useful because:
- The noise tends to cancel out in large datasets.
- Researchers know exactly how much noise was added and can mathematically adjust results.
- Larger sample sizes lead to more accurate patterns.
Noise in data ensures we can analyze patterns and trends while safeguarding individual privacy. This balance is crucial in fields like healthcare, location tracking, and even improving smartphone features, demonstrating how differential privacy is shaping the future of data analysis.