-
Notifications
You must be signed in to change notification settings - Fork 5
Home
This is the Wiki for corenlp-clj, a wrapper for Stanford CoreNLP written in Clojure.
Stanford CoreNLP is a powerful tool for Natural Language Processing, but features a rather clunky design with lots of cruft built up over the years. This library seeks to apply a lighter and more functional style to its API, while still retaining direct use of the data structures found in the Java version. The design is inspired in particular by Rich Hickey's Simple Made Easy concept.
A secondary goal of the project is to provide sensible documentation for newcomers to NLP. Stanford CoreNLP is not a beginner-friendly tool, but corenlp-clj aims to be just that while still remaining powerful.
(ns example-project.core
(:require [corenlp-clj.core :refer [pipeline prerequisites]]
[corenlp-clj.annotations :refer [sentences dependencies]]
[corenlp-clj.semgraph :refer [view]]))
(def nlp (pipeline {"annotators" (prerequisites "depparse")}))
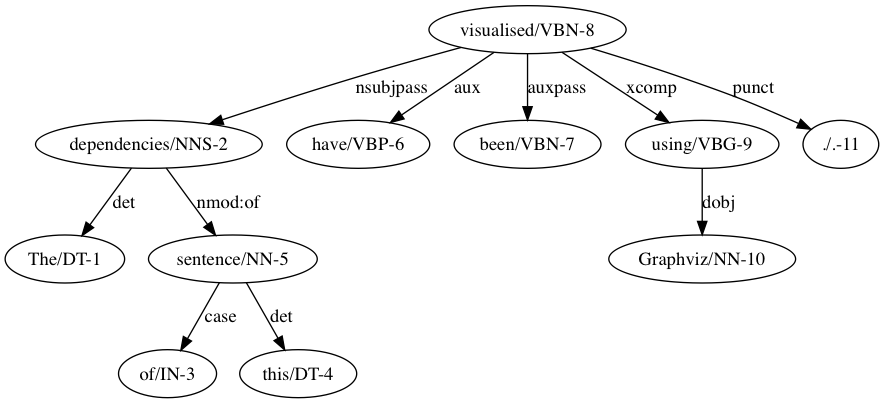
(view (->> "The dependencies of this sentence have been visualised using Graphviz."
nlp
sentences
dependencies
first))Check out the dependency graph that was generated in this short example. For an introduction to corenlp-clj, please refer to the tutorial!
{kind=link}
As a general rule function names reflect the output of the function, e.g. pos outputs a part-of-speech, text outputs some text, dependency-graph outputs a dependency graph, and sentences outputs a seq of sentences.
The output of function whose names end with an s will typically have seqable output. In the case of chaining annotation functions together this does not matter, as seqable function outputs are mapped automatically by the next function in the chain. This principle results in conceptually clear code from the input to the output. The dimensionality of the final array can be gauged by counting how many function names are in plural.
The development of this library is driven right now by my own needs for sensible implementations of CoreNLP functionality related to parts-of-speech and dependency graphs in Chinese. The base pipeline is ready for any kind of annotation work -- all of which can be accessed using a set of common functions -- and I'm working on implementing specific functionality in the semgraph package at the moment.
- CoreNLP in the browser (including semgrex): http://corenlp.run/
- Languages bindings: https://stanfordnlp.github.io/CoreNLP/other-languages.html