![]()
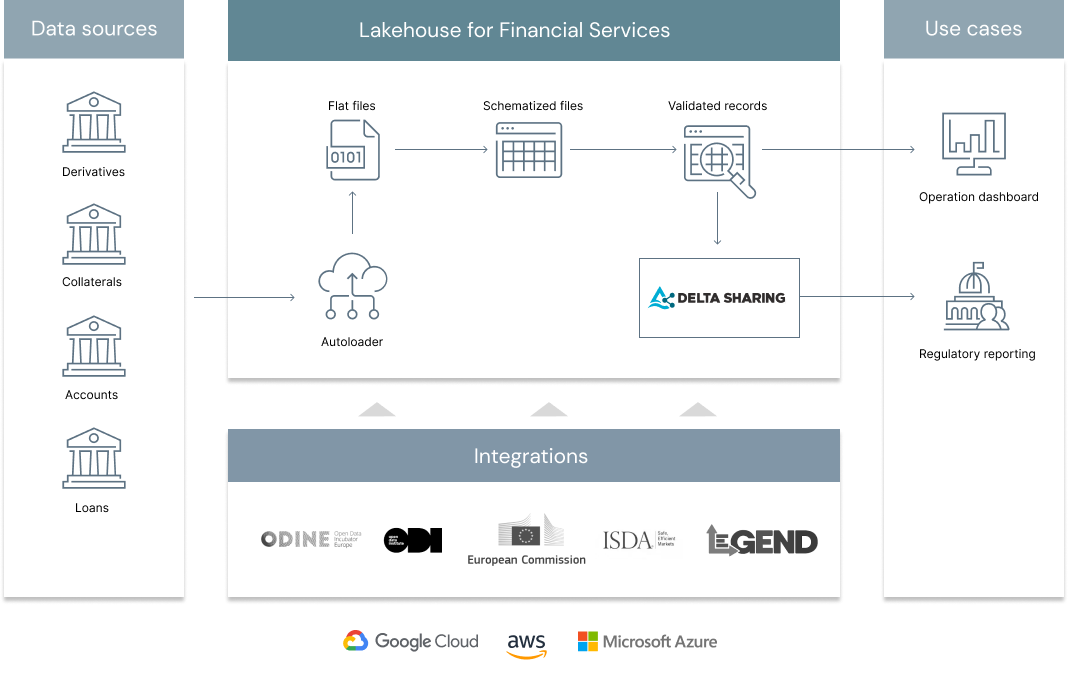
In today’s interconnected world, managing risk and regulatory compliance is an increasingly complex and costly endeavour. Regulatory change has increased 500% since the 2008 global financial crisis and boosted regulatory costs in the process. Given the fines associated with non-compliance and SLA breaches (banks hit an all-time high in fines of $10 billion in 2019 for AML), processing reports has to proceed even if data is incomplete. On the other hand, a track record of poor data quality is also "fined" because of "insufficient controls". As a consequence, many FSIs are often left battling between poor data quality and strict SLA, balancing between data reliability and data timeliness. In this solution accelerator, we demonstrate how Delta Live Tables can guarantee the acquisition and processing of regulatory data in real time to accommodate regulatory SLAs and, coupled with Delta Sharing, to provide analysts with a real time confidence in regulatory data being transmitted. Through these series notebooks and underlying code, we will demonstrate the benefits of a standardized data model for regulatory data coupled the flexibility of Delta Lake to guarantee both reliability and timeliness in the transmission, acquisition and calculation of data between regulatory systems in finance
© 2022 Databricks, Inc. All rights reserved. The source in this notebook is provided subject to the Databricks License [https://databricks.com/db-license-source]. All included or referenced third party libraries are subject to the licenses set forth below.
| library | description | license | source |
|---|---|---|---|
| FIRE | Regulatory models | Apache v2 | https://github.com/SuadeLabs/fire |
| waterbear | data model lib | Databricks | https://github.com/databrickslabs/waterbear |
| PyYAML | Reading Yaml files | MIT | https://github.com/yaml/pyyaml |
To run this accelerator, clone this repo into a Databricks workspace. Switch to the web-sync branch if you would like to run the version of notebooks currently published on the Databricks website. Attach the RUNME notebook to any cluster running a DBR 11.0 or later runtime, and execute the notebook via Run-All. A multi-step-job describing the accelerator pipeline will be created, and the link will be provided. Execute the multi-step-job to see how the pipeline runs. The job configuration is written in the RUNME notebook in json format. The cost associated with running the accelerator is the user's responsibility.