-
Notifications
You must be signed in to change notification settings - Fork 4
/
Copy pathbert_hatespeech_portuguese.py
734 lines (533 loc) · 27.2 KB
/
bert_hatespeech_portuguese.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
# -*- coding: utf-8 -*-
"""Copy of Hatespeech BERT Portuguese.ipynb
Automatically generated by Colaboratory.
Original file is located at
https://colab.research.google.com/drive/1f3fFw1rsOeNR7IVBtHoSd6BvLD5Fclrx
# Instalar o HuggingFace
https://huggingface.co/
"""
!pip install transformers
!pip uninstall tokenizers
!pip install tokenizers
"""#Importar o Pytorch e HuggingFace (transformers e tokenizers)"""
import torch
from transformers import BertModel, BertForMaskedLM, PreTrainedTokenizer
from tokenizers import BertWordPieceTokenizer
"""#Configura o ambiente para usar GPU (CUDA)"""
if torch.cuda.is_available():
# Tell PyTorch to use the GPU.
device = torch.device("cuda")
print('There are %d GPU(s) available.' % torch.cuda.device_count())
print('We will use the GPU:', torch.cuda.get_device_name(0))
# If not...
else:
print('No GPU available, using the CPU instead.')
device = torch.device("cpu")
"""OPCIONAL: Pode ativar um debbug para entender melhor o que acontece"""
import logging
logging.basicConfig(level=logging.INFO)
"""Carrega um modelo de Tokenizer pré-treinado (neste caso o Multilanguage para trabalhar com português)
#Download do Dataset de treinamento
Fazer o download do CoLA Dataset ( The Corpus of Linguistic Acceptability (CoLA)). Um dataset em inglês para classificação simples: se a senteça está gramaticalmente correta ou não (parte do GLUE Benchmark)
Instala o Wget para fazer o download
"""
#instal o wget para fazer o dowload
!pip install wget
"""O dataset que vamos utilizar foi produzido pela pesquisadora portuguesa Paula Fortuna, durante sua dissertação de mestrado na Universidade do Porto. O resultado foi publicado na ACL 2019. Os dados estão disponíveis em: https://github.com/paulafortuna/. Precisamos fazer o download:"""
import wget
import os
print('Downloading dataset...')
# The URL para o CSV com o dataset
if not os.path.exists('2019-05-28_portuguese_hate_speech_binary_classification.csv'):
url = 'https://raw.githubusercontent.com/paulafortuna/Portuguese-Hate-Speech-Dataset/master/2019-05-28_portuguese_hate_speech_binary_classification.csv'
wget.download(url)
#from google.colab import drive
#drive.mount('/content/drive')
"""#Pre-processando o Dataset
Na pasta, existem duas pastas. Precisamos usar os dados brutos (raw) para que possamos criar os token usando o BertTokenizer. Não podemos usar as setenças tokenizadas porque o processo utilizado na criação desses tokens foi diferente do usado pelo Bert.<br>
Iremos utilizar o pandas para manipular as entradas.
"""
#Importa o pandas
import pandas as pd
#Carrega o dataset de treinamento para um dataframe
df = pd.read_csv('2019-05-28_portuguese_hate_speech_binary_classification.csv', delimiter=',')
#mostra as 5 primeiras linhas do dataframe
df.head(50)
"""Como visto, o dataset possui diversos campos de registro das anotações. <br> O que nos interessa, no entanto, são os campos do texto "text" e a classificação final "hatespeech_comb".
Abaixo podemos listar 5 exemplos de setenças com ódio :
"""
df.loc[df.hatespeech_comb == 1].sample(5)
"""E 5 exemplos de sentenças sem ódio"""
df.loc[df.hatespeech_comb == 0]. sample(5)
"""Podemos criar dos arrays (Numpy Array) para armazenar as setenças e os labels. Também vamos deixar todos os textos em letras minúsculas:"""
import numpy as np
# DataFrame.value retorna uma representação Numpy
sentencas1 = df['text'].values
labels1 = df['hatespeech_comb'].values
# ADICIONANDO UM SEGUNDO DATASET
if not os.path.exists('OffComBR2.arff'):
wget.download('https://raw.githubusercontent.com/diogocortiz/BERT-Portuguese-hate-speech/master/OffComBR2.csv')
if not os.path.exists('OffComBR2.arff'):
wget.download("https://raw.githubusercontent.com/diogocortiz/BERT-Portuguese-hate-speech/master/OffComBR3.csv")
df = pd.read_csv('OffComBR2.csv', names=['label', 'sentence'])
# O LABEL ESTÁ COM YES/NO, PODEMOS MODIFICAR PARA 1 e )
# USANDO A FUNÇÃO REPLACE DO PANDAS
df['label'].replace('yes', 1, inplace=True)
df['label'].replace('no', 0, inplace=True)
# TRANSFORMA DE DATAFRAME PARA NUMPY ARRAY
labels2 = df['label'].values
sentencas2 = df['sentence'].values
if not os.path.exists('OffComBR2.arff'):
wget.download("https://raw.githubusercontent.com/diogocortiz/BERT-Portuguese-hate-speech/master/OffComBR3.csv")
df = pd.read_csv('OffComBR3.csv', names=['label', 'sentence'])
# O LABEL ESTÁ COM YES/NO, PODEMOS MODIFICAR PARA 1 e )
# USANDO A FUNÇÃO REPLACE DO PANDAS
df['label'].replace('yes', 1, inplace=True)
df['label'].replace('no', 0, inplace=True)
labels3 = df['label'].values
sentencas3 = df['sentence'].values
# CONCATENA OS DOIS DATASET
#labels = np.concatenate((labels1, labels2))
#sentencas = np.concatenate((sentencas1, sentences2))
labels = np.copy(labels1)
sentencas = np.copy(sentencas1)
# MOSTRANDO O TIPO DE DADOS (Numpy Array)
print(type(sentencas1))
# MODIFICANDO AS SETENÇAS PARA TODAS AS LETRAS MINÚSCULAS
#print(len(sentencas))
#for x in range (len(sentencas)):
# sentencas[x] = sentencas[x].lower()
#print(sentencas[7])
"""#Formatando a Entrada e Criando os Tokens e IDS
Agora chegou a hora de criarmos os tokens para que depois eles possam ser mapeados para os index do vocabulário.<Br>
Para isso, utilizaremos o BertTokenizer, que já importamos anteriormente. Utilizaremos a versão 'bert-based-unscased' (inglês).<br>
Antes disso, no entanto, precisamos formatar a entrada para respeitar os requisitos de entrada do Bert, que são os seguintes:
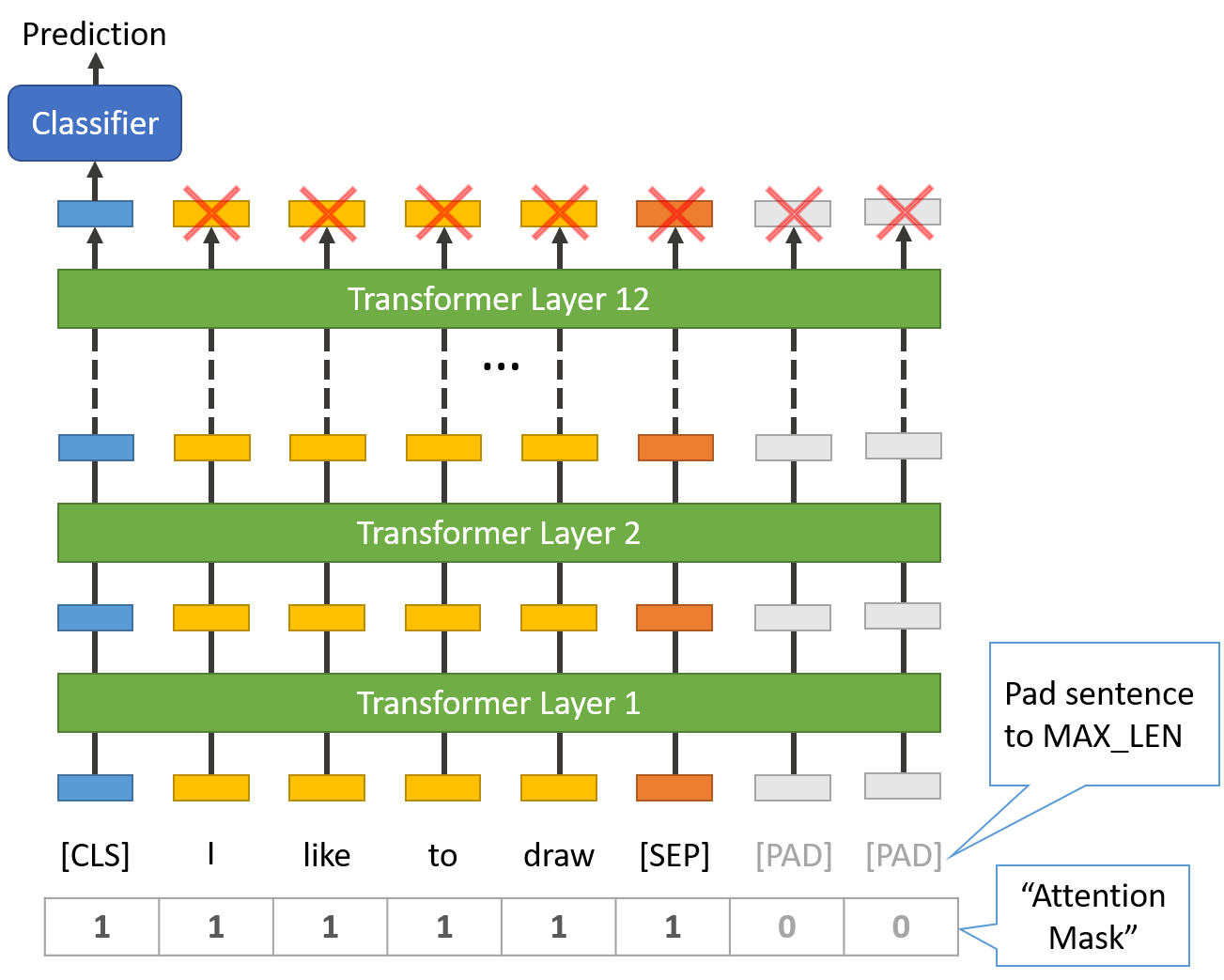
1. Adicionar tokens especiais no início e no fim de cada sentença ([CLS] para o início de uma sentença de classificação / [SEP] para indicar o fim de uma sentença.
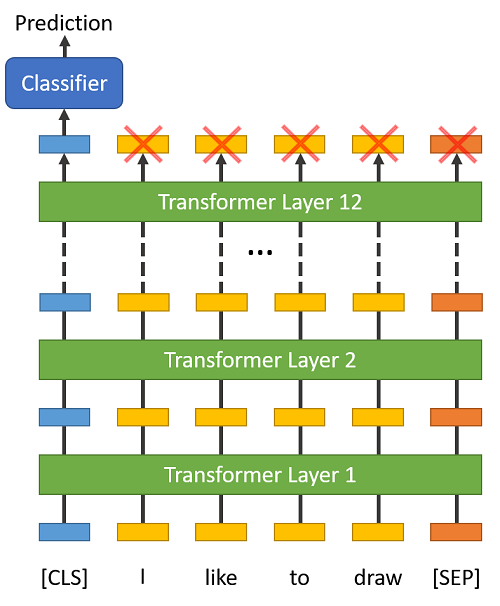
2. Precisamos fazer o Pad e Truncate para que todas as senteças tenham o mesmo tamanho de entrada (máximo de 512 tokens).
3. Diferenciar o que são tokens reais dos token de padding, criando um "attention mask".
#Entendendo o Tokenizer<br>
O modelo do Google tem um vocabulário de 30.000 tokens com aprox 768 dimensões cada (embeedings).<br>
Os Tokens podem representar palavras completas (mas não todas) <br>
Os Tokens podem representar sub-palavras de palavras desconhecidas (as subwords são iniciadas com ##. Reparem que a palavra Diogo não existe no vocabulário. Ela é quebrada em duas subwords: Dio + ##go. Atenção: O token go é diferente do ##go) <oov><br>
Os Tokens podem representar caracteres e marcações especiais:<br>
[PAD]: Padding<br>
[UNK]:Unknow<br>
[CLS]: Classificação<br>
[SEP]: Separação das sentenças<br>
[MASK]: Máscara para a palavra<br>
"""
# USA O MODULO TOKENIZER DO HUGGINFACE
from tokenizers import (ByteLevelBPETokenizer,
SentencePieceBPETokenizer,
BertWordPieceTokenizer)
# FAZ O DOWNLOAD DO VOCABULÁRIO
if not os.path.exists('vocab.txt'):
wget.download("https://neuralmind-ai.s3.us-east-2.amazonaws.com/nlp/bert-base-portuguese-cased/vocab.txt")
# FAZ O DOWNLOAD DO PRE-TREINADO EM PT-BT
if not os.path.exists('bert-base-portuguese-cased_pytorch_checkpoint.zip'):
wget.download("https://neuralmind-ai.s3.us-east-2.amazonaws.com/nlp/bert-base-portuguese-cased/bert-base-portuguese-cased_pytorch_checkpoint.zip")
!unzip bert-base-portuguese-cased_pytorch_checkpoint.zip -d bert-portuguese
# CRIA O TOKENIZER A PARTIR DE UM VOCABULÁRIO
# LOWERCASE = FALSE (NÃO IRÁ CONVERTER AS ENTRADAS PARA LOWERCASE. MANTEM O ORGINIAL)
# STRIP ACCENTS = FALSE (MANTEM OS ACENTOS)
tokenizer = BertWordPieceTokenizer("vocab.txt", lowercase=False, strip_accents=False)
# MOSTRA AS INFORMAÇÕES DO TONENIZER
print(tokenizer)
# PERMITE O TRUNCATION E O PADDING
tokenizer.enable_truncation(max_length=60)
tokenizer.enable_padding()
# TOKENINZA EM BATCH TODAS AS SENTENÇAS
# TEM QUE USAR .TOLIST PARA CONVERTER POR LISTA. SENTENCAS É UM ARRAY NUMPY
output = tokenizer.encode_batch(sentencas.tolist())
# O TOKENIZER RETORAR UMA LISTA DE OBJETOS DO TIPO TOKENIZER
# PRECISAMOS PEGAR OS ATRIBUTOS IDS E MASKS E ADICIONAR PARA LISTAS
# OS OBJETOS TEM O ATRIBUTO IDS(IDS), TOKENS (TOKENS) E attention_mask
# PRECISAMOS FAXER O FOR PARA PEGAR CADA UM E DEPOIS CRIAR A LISTA
ids=[x.ids for x in output]
attention_mask = [x.attention_mask for x in output]
print(len(ids))
print(len(attention_mask))
# PRINTS EXEMPLO DE SAIDA DA PRIMEIRA LINHA
print(output[0])
print(output[0].tokens)
"""#Dividindo o Dataset em Treinamento e Validação
Vamos usar a ferramenta do ScikitLearn para nos ajudar neste processo. Vamos dividir o dataset em 80% para treinamento e 20% para a validação
"""
from sklearn.model_selection import train_test_split
#USAR O MESMO RANDON_STATE PARA NAO TROCAR OS INPUTS DE SUAS MÁSCARAS
train_input, validation_input, train_labels, validation_labels = train_test_split(ids, labels, random_state=2018, test_size=0.2)
train_mask, validation_mask, _, _ = train_test_split(attention_mask, labels, random_state=2018, test_size=0.2)
#COMPARANDO A PRIMEIRA LINHA DE TREINAMENTO COM A MASCARA
print(train_input[0])
print(train_mask[0])
"""#Criando os tensores (Pytorch Data Type)
Os modelos do PyTorch esperam de entrada o tipo tensor, então precisamos converter o nosso dataset de Numpy Array para tensores.
"""
train_input_tensor = torch.tensor(train_input)
validation_input_tensor = torch.tensor(validation_input)
train_labels_tensor = torch.tensor(train_labels)
validation_labels_tensor = torch.tensor(validation_labels)
train_mask_tensor = torch.tensor(train_mask)
validation_mask_tensor= torch.tensor(validation_mask)
"""Uma ação adicional é usar o torch DataLoade, que cria um "iterator". Diferente de um for, o iterador não sobe todo o dataset não precisa ser carregado todo na memória (ajuda no treinamento)"""
from torch.utils.data import TensorDataset, DataLoader, RandomSampler, SequentialSampler
#É PRECISO ESPECIFICAR O TAMANHO DO BATCH, PARA O BERT OS AUTORES RECOMENDAM 16 OU 32
batch_size = 32
#CRIA OS DATALOADERS PARA O CONJUNTO DE TREINAMENTO
train_data = TensorDataset(train_input_tensor, train_mask_tensor, train_labels_tensor)
train_sampler = RandomSampler(train_data)
train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=batch_size)
#CRIA OS DATALOADRES PARA O CONJUNTO DE VALIDAÇÃO
validation_data = TensorDataset(validation_input_tensor, validation_mask_tensor, validation_labels_tensor)
validation_sampler = SequentialSampler(validation_data)
validation_dataloader = DataLoader(validation_data, sampler=validation_sampler, batch_size=batch_size)
"""#Treinando o modelo
O Bert oferece um modelo pré-treinando a qual só precisamos fazer fine-tune para a tarefas que desejamos. O huggingface disponibiza não só o modelo pré-treinado mas também interfaces para nossas tarefas específicas. Algumas disponíveis são:
* BertMode
* BertForMaskedLM
* BertForNextSentencePrediction
* BertForSequenceClassification (vamos usar este)
* BertForTokenClassification
* BertForQuestionAnsering
O BerForSequenceClassification basicamente é a implementação do modelo Bert com a adição de uma camada de FFN para classificação. Lembre-se que o huggieface disponibilizou diversas versões de modelo pré-treinanda (base, large, multilanugage). Você pode escolher a que for melhor para o seu propósito. Neste caso, vamos utilizar a versão multilingual por contemplar o português.
"""
#IMPORTA O BERT E O OTIMIZADOR ADAM
from transformers import BertForSequenceClassification, AdamW, BertConfig, BertModel
#CRIA O MODELO BERT PRETREINADO COM UMA CAMADA DE CLASSIFICAÇÃO NO TOPO
model = BertForSequenceClassification.from_pretrained(
'bert-portuguese',
num_labels = 2, # NUMERO DE CLASSES (NO CASO BINÁRIA: ACEITÁVEL OU NÃO. PODE TER MAIS PARA MULTICLASSE)
output_attentions = True, # SE O MODELO DEVE EXPORTAR OS PESOS DAS ATENÇÕES
output_hidden_states = True, # SE O MODELO DEVE EXPORTAR OS HIDDEN STATES (PODE SER INTERESSANTE PARA ESTUDAR EMBEDDINGS)
)
#DIZ AO MODELO PARA USAR GPU
model.cuda()
"""**CURIOSDIADE.**
Uma curiosidade disponibilizada em (https://mccormickml.com/2019/07/22/BERT-fine-tuning/) <br>
É possível mostrar os parâmetro do modelo:
<br>
* A camada de embeddings
* A primeira das 12 camadas de transformers
* A camada de saída (output)
A execução do trecho abaixo é optativa.
"""
# Get all of the model's parameters as a list of tuples.
params = list(model.named_parameters())
print('The BERT model has {:} different named parameters.\n'.format(len(params)))
print('==== Embedding Layer ====\n')
for p in params[0:5]:
print("{:<55} {:>12}".format(p[0], str(tuple(p[1].size()))))
print('\n==== First Transformer ====\n')
for p in params[5:21]:
print("{:<55} {:>12}".format(p[0], str(tuple(p[1].size()))))
print('\n==== Output Layer ====\n')
for p in params[-4:]:
print("{:<55} {:>12}".format(p[0], str(tuple(p[1].size()))))
"""**Otimizador**
Carregamos o modelo, agora precisamos criar o Otimizador Adam. Os autores recomendam os seguintres valores:
* Batch Size: 16, 32 (Lembre-se que usamos 32 no Dataloader)
* Learning Rate (Adam): 5e-5, 3e-5, 2e-5 (vamos usar 2e-5)
* Numero de épocas (Quantas vezes TODO o dataset é treinado): 2,3,4 (utilizaremos 4):
"""
#ADAMW É A CLASSE DO HUGGINGFACE
optimizer = AdamW(model.parameters(),
lr = 2e-5, # args.learning_rate - default is 5e-5, our notebook had 2e-5
eps = 1e-8 # args.adam_epsilon - default is 1e-8.
)
"""**Learning Rate Scheduler**
Em redes neurais é útil diminuir a taxa de aprendizado (learning rate) conforme as épocas vão aumentando para que possamos evitar que o modelo entre em um estado "caótico" com taxas grandes ou o "falso míninmo" com taxas pequenas. A ideia é ir ajustando conforme as épocas vão passando.
"""
#ESTA CLASSE FARÁ O AGENDAMENTO
from transformers import get_linear_schedule_with_warmup
epochs = 4 #QUANTIDADE DE ÉPOCAS
#PARA CALCULAR A QUANTIDADE DE PASSOS É A QTD DE BATCHS * ÉPOCAS
total_steps = epochs * len(train_dataloader)
#CRIANDO O AGENDADOR
scheduler = get_linear_schedule_with_warmup(optimizer,
num_warmup_steps = 0, #VALOR PADRÃO
num_training_steps = total_steps)
"""**Loop de Treinamento**
Não é só chamar alguma função para treinar o modelo. Precisamos criar um loop que se repita a quantidade de épocas especificadas executando as atividades abaixo. A cada passagem, também faremos uma avaliação do modelo:
Loop de treinamento
* Desempacotar os dados de entrada e os labels
* Carregar os dados para a GPU
* Limpar os gradientes calculados na passagem anterior (no pytorch os gradientes são acumulados por padrão. pode ser útil para RNN, mas não no caso de transformers.
* Forward Pass (Passar os dados pela rede)
* Backward Pass (backpropagation)
* Pedir para a rede atualizar os parâmetros (optimizer.step())
* Monitar as variáveis para saber o progresso
Loop de avaliação
* Desempacotar os dados de entrada e os labels
* Carregar os dados para a GPU
* Forward Pass (Passar os dados pela rede)
* Computar a perda na nossa validação e monitorar as variáveis para saber o progresso.
**Antes, vamos criar duas funções de ajuda. Uma para calcular a acurácia do modelo e outra para formatar o horário**:
"""
import numpy as np
import time
import datetime
# FUNÇÃO QUE CALCULA A ACURÁCIA DO MODELO (PREDIÇÕES vs LABELS)
def flat_accuracy(preds, labels):
pred_flat = np.argmax(preds, axis=1).flatten()
labels_flat = labels.flatten()
return np.sum(pred_flat == labels_flat) / len(labels_flat)
# FUNÇÃO QUE FORMATA O HORÁRIO
def format_time(elapsed):
'''
Takes a time in seconds and returns a string hh:mm:ss
'''
# Round to the nearest second.
elapsed_rounded = int(round((elapsed)))
# Format as hh:mm:ss
return str(datetime.timedelta(seconds=elapsed_rounded))
"""**AGORA VEM O LOOP DE TREINAMENTO :)**"""
import random
# PRIMEIRO PRECISAMOS GARANTIR A REPRODUTIBILIDADE
# USANDO OS SEEDS DO PYTORCH, GARANTIMOS QUE OS VALORES SERÃO INICIADOS DA MESMA FORMA
# VAMOS SETAR O MESMO VALOR EM DIFERENTES LUGARES
seed_val = 42
random.seed(seed_val)
np.random.seed(seed_val)
torch.manual_seed(seed_val)
torch.cuda.manual_seed_all(seed_val)
# CRIANDO UMA LISTA QUE IRÁ ARMZENAR LOSS AO FIM DE CADA ÉPOCA
loss_values = []
# CRIANDO O LOOP DAS ÉPOCAS
for epoch_i in range(0, epochs):
# ========================================
# Training
# ========================================
# Perform one full pass over the training set.
print("")
print('======== Epoch {:} / {:} ========'.format(epoch_i + 1, epochs))
print('Training...')
# MEDIR QUANTO TEMPO UMA ÉPOCA LEVA
t0 = time.time()
# RESETANDO O LOSS PARA ESTA ÉPOCA
total_loss = 0
#COLOCANDO O MODELO NO MODO DE TREINAMENTO
#ESSE COMANDO NÃO CHAMA O TREINAMENTO, APENAS AVISA O MODELO PARA FAZER AJUSTES DE DROPOUTS
model.train()
device = torch.device("cuda")
# UM LOOP PARA CADA BATCH DENTRO DA ÉPOCA
for step, batch in enumerate(train_dataloader):
# PRECISAMOS DESPEMPACOTAR O BATCH E CARREGAR NA GPU
# BATCH CONTEM TRÊS TENSORES
# [0]: ID DE INPUT
# [1]: ATTENTION MASKS
# [2]: LABELS
b_input_ids = batch[0].to(device)
b_input_mask = batch[1].to(device)
b_labels = batch[2].to(device)
#PRECISAMOS LIMPAR O GRADIENTE ANTES DE BACKPROP
#PYTORCH NAO FAZ ISSO AUTOMÁTICO
model.zero_grad()
#AGORA VAMOS FAZER UMA PASSAGEM (FORWARD PASS)
#O RESULTADO SERÁ LOSS (NÃO SERÁ A PREDIÇÃO PQ PASSAMOS OS LABELS)
outputs = model(b_input_ids,
token_type_ids=None, #USADO QUANDO É NEXT SEQUENCE
attention_mask=b_input_mask,
labels=b_labels)
#O MODELO RETORNA UMA TUPLA.
#VAMOS PEGAR O VALOR DA TUPLA
loss = outputs[0]
hidden_state = outputs[2]
# VAMOS ARMAZENAR O HIDDEN STATE E ATENÇÃO TB
#VAMOS ACUMULAR O VALOR NO TOTAL DE LOSS DA ÉPOCA
# .item() RETORNA UM VALOR PYTHON DE UM TENSOR
total_loss += loss.item()
#AGORA VAMOS FAZER O BACKWARD PARA CALCULAR O GRADIENTE
loss.backward()
# PASSO NECESSÁRIO
# Clip the norm of the gradients to 1.0.
# This is to help prevent the "exploding gradients" problem.
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
# O OTIMIZADOR VAI ATUALIZAR OS PARAMETROS COM BASE NO GRADIENTE
optimizer.step()
# ATUALIZANDO O LEARNING RATE
scheduler.step()
# APOS TODOS OS BATCH DE UMA EPOCA
# CACLULA AVERAGE LOSS COM BASE NO TREINAMENTO (TAMANHO DO DATASET)
avg_train_loss = total_loss / len(train_dataloader)
#ARMAZENA O LOSS NA LISTA (PARA DEPOIS SER PLOTADO NO GRAFICO)
loss_values.append(avg_train_loss)
# DENTRO DE CADA ÉPOCA TAMBÉM VAMOS RODAR UMA AVALIAÇÃO
print("Running Validation...")
t0 = time.time()
# COLOCANDO O MODELO NO MODO DE AVALIAÇÃO (SAINDO DO MODULO DE TREINAMENTO)
model.eval()
# CRIANDO VARIÁVEIS DE MONITORAMENTO
eval_loss, eval_accuracy = 0, 0
nb_eval_steps, nb_eval_examples = 0, 0
# LOOP PARA AVALIAR CADA BATCH DE TREINAMENTO
for batch in validation_dataloader:
b_input_ids = batch[0].to(device)
b_input_mask = batch[1].to(device)
b_labels = batch[2].to(device)
# PEDE AO MODELO PARA NAO COMPUTAR GRADIENTES (É VALIDAÇÃO, NÃO TREINAMENTO)
with torch.no_grad():
# FORWARD PASS PARA CALCULAR OS LOGITS DA PREDIÇÃO
outputs = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask)
# O RESULTADO DO MODELO AGORA NÃO SERÁ LOSS
# SERÁ 'LOGITS', VALOR DE SAIDA ANTES DE UMA FUNÇÃO DE ATIVAÇÃO (SOFTMAX POR EXEMPLO)
# COMO É UMA CLASSIFICAÇÃO BINÁRIA, SÓ OS LOGITS SERVEM
# DEPENDENDO DO MODELO SERIA NECESSÁRIO UM SOFTMAX
logits = outputs[0]
# MOVER OS LOGITS E OS LABELS PARA A CPU
logits = logits.detach().cpu().numpy()
label_ids = b_labels.to('cpu').numpy()
#CALCULAR ACURÁCIA CHAMANDO A FUNÇÃO QUE CRIAMOS ANTERIORMENTE
tmp_eval_accuracy = flat_accuracy(logits, label_ids)
# ACUMULAR O TOTAL DA ACURÁCIA
eval_accuracy += tmp_eval_accuracy
# TRACKEAR O NUMERO DE BATCHS
nb_eval_steps +=1
# EXIBINDO DADOS FINAIS
print(" Acurácia: {0:.2f}".format(eval_accuracy/nb_eval_steps))
print(" Tempo de Validação: {:}".format(format_time(time.time() - t0)))
#FIM DAS EPOCAS
print("FIM DO TREINAMENTO")
"""** Mostrando o gráfico LOSS por época **"""
# Commented out IPython magic to ensure Python compatibility.
import matplotlib.pyplot as plt
# % matplotlib inline
import seaborn as sns
# Use plot styling from seaborn.
sns.set(style='darkgrid')
# Increase the plot size and font size.
sns.set(font_scale=1.5)
plt.rcParams["figure.figsize"] = (12,6)
# Plot the learning curve.
plt.plot(loss_values, 'b-o')
# Label the plot.
plt.title("Training loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.show()
"""#Executando e Testando o modelo
Agora que o modelo está treinado, podemos executá-lo. Nesta seção vamos fazer alguns testes. O primeiro ponto é preparar os dados (assim como fizemos na fase de treinamento), mas desta vez não precisamos dos labels.
"""
# FUNÇÃO QUE VALIDA O MODELO
def Validar_Modelo(prediction_dataloader, batch_size):
#ARMAZENAR RESULTADOS
resultado_predicoes = []
resultados_esperados = []
falsos_positivos = []
falsos_negativos = []
verdadeiros_positivos = []
verdadeiros_negativos =[]
nb_eval_steps = 0
eval_accuracy = 0
tmp_eval_accuracy = 0
for batch in prediction_dataloader:
b_input_ids = batch[0].to(device)
b_input_mask = batch[1].to(device)
b_labels = batch[2].to(device)
# PEDE AO MODELO PARA NAO COMPUTAR GRADIENTES (É VALIDAÇÃO, NÃO TREINAMENTO)
with torch.no_grad():
# FORWARD PASS PARA CALCULAR OS LOGITS DA PREDIÇÃO
outputs = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask)
# O RESULTADO DO MODELO AGORA NÃO SERÁ LOSS
# SERÁ 'LOGITS', VALOR DE SAIDA ANTES DE UMA FUNÇÃO DE ATIVAÇÃO (SOFTMAX POR EXEMPLO)
# COMO É UMA CLASSIFICAÇÃO BINÁRIA, SÓ OS LOGITS SERVEM
# DEPENDENDO DO MODELO SERIA NECESSÁRIO UM SOFTMAX
# TAMBÉM É POSSIVEL PEGAR A ATENÇÃO E OS HIDDEN STATES
logits = outputs[0]
attention=outputs[-1]
all_hidden_state = outputs[-2]
# MOVER OS LOGITS E OS LABELS PARA A CPU
logits = logits.detach().cpu().numpy()
label_ids = b_labels.to('cpu').numpy()
reconstruct_input_id = b_input_ids.to('cpu').numpy()
# LOOP PARA VISUALIZAR CADA SETENÇA
for logit, label, inputs, att in zip(logits, label_ids, reconstruct_input_id, attention):
resultado_predicoes.append(np.argmax(logit))
resultados_esperados.append(label)
# LOOP PARA IDENTIFICAR FALSOS POSITIVIOS, FALSOS NEGATIVOS e CORRETOS
if (label != np.argmax(logit)):
if (label == 1 and np.argmax(logit) == 0):
falsos_negativos.append(inputs)
#captum(inputs,label,logit, "fn")
elif(label == 0 and np.argmax(logit) == 1):
falsos_positivos.append(inputs)
#captum(inputs,label,logit, "fp")
else:
if (label == 1 and np.argmax(logit) == 1):
verdadeiros_positivos.append(inputs)
#captum(inputs,label,logit, "tp")
elif (label == 0 and np.argmax(logit) == 0):
verdadeiros_negativos.append(inputs)
#captum(inputs,label,logit, "tn")
#CALCULAR ACURÁCIA CHAMANDO A FUNÇÃO QUE CRIAMOS ANTERIORMENTE
tmp_eval_accuracy = flat_accuracy(logits, label_ids)
# ACUMULAR O TOTAL DA ACURÁCIA
eval_accuracy += tmp_eval_accuracy
# TRACKEAR O NUMERO DE BATCHS
nb_eval_steps +=1
#wait = input("PRESS ENTER TO CONTINUE.")
# RELATÓRIO FINAL
print(" Accuracy: {0:.2f}".format(eval_accuracy/nb_eval_steps))
from sklearn.metrics import accuracy_score
print("Accuracia: ", accuracy_score(resultados_esperados, resultado_predicoes))
from sklearn.metrics import f1_score
print("F1 Score:", f1_score(resultados_esperados, resultado_predicoes, average='weighted'))
from sklearn.metrics import recall_score
print("Recall:", recall_score(resultados_esperados, resultado_predicoes, average='weighted'))
from sklearn.metrics import precision_score
print("Precision: ", precision_score(resultados_esperados, resultado_predicoes, average='weighted'))
#listar_falsospositivos(falsos_positivos)
#attrib2csv(attrib_falsospositivo, "falsos_positivos.csv")
#attrib2csv(attrib_falsosnegativos, "falsos_negativos.csv")
#attrib2csv(attrib_verdadeirospositivos, "verdadeiros_positivos.csv")
#attrib2csv(attrib_verdadeironegativos, "verdadeiros_negativos.csv")
from sklearn.metrics import confusion_matrix
tn, fp, fn, tp = confusion_matrix(resultados_esperados, resultado_predicoes).ravel()
print ("True Negative: ", tn)
print ("False Positive: ", fp)
print ("False Negative: ", fn)
print ("True Positive: ", tp)
"""#Tratando os dados para chamar a validação"""
# DATABASE PAULA
#df = pd.read_csv('2019-05-28_portuguese_hate_speech_binary_classification.csv', delimiter=',')
#sentencas = df['text'].values
#labels = df['hatespeech_comb'].values
wget.download("https://raw.githubusercontent.com/diogocortiz/BERT-Portuguese-hate-speech/master/OffComBR3.csv")
#DATABASE DE PELLES
df = pd.read_csv('OffComBR3.csv', names=['label', 'sentence'])
# O LABEL ESTÁ COM YES/NO, PODEMOS MODIFICAR PARA 1 e )
# USANDO A FUNÇÃO REPLACE DO PANDAS
df['label'].replace('yes', 1, inplace=True)
df['label'].replace('no', 0, inplace=True)
# TRANSFORMA DE DATAFRAME PARA NUMPY ARRAY
labels = df['label'].values
sentencas = df['sentence'].values
tokenizer.enable_truncation(max_length=100)
tokenizer.enable_padding()
# TOKENINZA EM BATCH TODAS AS SENTENÇAS
# TEM QUE USAR .TOLIST PARA CONVERTER POR LISTA. SENTENCAS É UM ARRAY NUMPY
output = tokenizer.encode_batch(sentencas.tolist())
# O TOKENIZER RETORAR UMA LISTA DE OBJETOS DO TIPO TOKENIZER
# PRECISAMOS PEGAR OS ATRIBUTOS IDS E MASKS E ADICIONAR PARA LISTAS
# OS OBJETOS TEM O ATRIBUTO IDS(IDS), TOKENS (TOKENS) E attention_mask
# PRECISAMOS FAXER O FOR PARA PEGAR CADA UM E DEPOIS CRIAR A LISTA
ids=[x.ids for x in output]
tokens = [x.tokens for x in output]
attention_mask = [x.attention_mask for x in output]
# AGORA PRECISAMOS CONVERTER DE NUMPY PARA TENSOR
prediction_input = torch.tensor(ids)
prediction_mask = torch.tensor(attention_mask)
prediction_labels = torch.tensor(labels)
# GARANTINDO QUE TODOS OS CAMPOS TEM O MESMO TAMANHO
#print (prediction_input.size(0))
#print (prediction_mask.size(0))
#print (prediction_labels.size(0))
# DEFININDO O TAMANHO DO BATCH
batch_size = 32
# CRIANDO O DATALOADER
prediction_data = TensorDataset(prediction_input, prediction_mask, prediction_labels)
prediction_sampler = SequentialSampler(prediction_data)
prediction_dataloader = DataLoader(prediction_data, sampler=prediction_sampler, batch_size=batch_size)
Validar_Modelo(prediction_dataloader, batch_size)
"""Salvar no GoogleDrive o status"""